转自:https://xz.aliyun.com/t/4931
原文地址:https://medium.com/@0xd0cf11e/analyzing-emotet-with-ghidra-part-1-4da71a5c8d69
https://medium.com/@0xd0cf11e/analyzing-emotet-with-ghidra-part-2-9efbea374b14
在本文中,我们将为读者演示如何使用Ghidra来分析恶意软件Emotet的最新样本。
需要说明的是,我们的分析工作是在脱壳后的二进制文件的基础上完成的。由于这里主要是为读者展示如何使用Ghidra的python脚本管理器来对字符串和API调用进行解密,所以,具体的脱壳过程,就不再这里介绍了。
概述
什么是Ghidra?
- Ghidra是一个开源的逆向工程工具套件,关于它的详细介绍,请参阅https://ghidra-sre.org/。
为何选择Emotet?
- Emotet是一种流行的银行木马恶意软件。该木马的生命力非常强,其感染机制还在不断进化。当前,已经有一些关于该恶意软件的分析文章,感兴趣的读者请访问https://www.google.com/search?q=emotet。
为什么使用Ghidra分析Emotet?
- 为啥?还不是因为IDA Pro许可证太贵,哥又不想放弃自己的恶意软件分析师职业生涯。
- 当然,使用免费版IDA v7.0也是一个不错的选择,但是这样的话,就无法使用IDA Python了。在试用一段时间IDA自家脚本语言IDC之后,我发现Python才是我的最爱。而Emotet不仅支持Python,还提供了许多现成的分析脚本。
使用Ghidra分析Emotet
在使用Ghidra时,首先要创建相应的项目。按照屏幕上的提示,我创建了一个名为“Emotet”的项目。要想将待分析的文件添加到项目中,只需键入I或选择File -> Import File菜单项。

导入Emotet的二进制文件
导入Emotet的二进制文件后,Ghidra将显示该文件的各种属性。之后,双击文件名,就会在CodeBrowser中打开该文件。在这里,CodeBrowser是一个反汇编工具。

CodeBrowser中的Emotet视图
在符号树下(通常显示在左侧;如果没有打开的话,可以通过window->symbol tree来打开它),通过过滤“entry”,就可以找到该二进制文件的入口点。
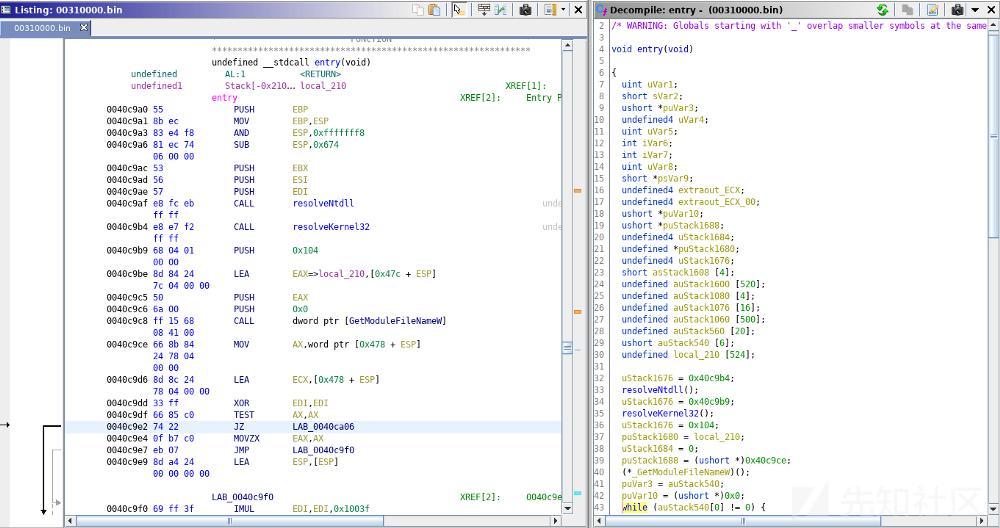
Emotet的入口点
在Listing窗口下面,我们可以看到编译后的代码,而右边显示的是反编译后的代码。由于之前已经对这些二进制文件进行了分析,因此,图中某些子例程调用和偏移量已经被我重命名了。当我们想要对偏移量进行重命名的时候,请右键单击相应的偏移量,然后,选择“Edit Label”(或键入L)即可。
Emotet的函数调用
Emotet不仅对自身的字符串进行了加密,同时,还将自身的API调用名称存储为哈希值形式。因此,静态查看该文件的内容的话,理解起来非常困难。
为了深入了解Emotet的payload,通常需要借助Olldbg、Wingdb或其他调试器来分析所有的函数,以弄清楚其内部运作机制。而本文的目标,就是如何利用Ghidra让这个过程更轻松一些。
下面,我们将展示如何利用Emotet弄清楚两个函数的运行机制。其中,第一个函数是一个简单的xor例程,用于解密字符串。表面上看,这个函数非常复杂(因为在函数中使用了移位运算符),直到在Ollydbg中运行一遍后,我才明白它到底是干什么的……第二个函数用于查找API名称与哈希值之间的对应关系(具体在后文中介绍)。当然,如果您觉得我说的还不够清楚的很,只要在Ollydbg中运行一下相应的代码,就能很好的理解了。
然后,我们将介绍Ghidra的脚本管理器,并展示如何通过python脚本来解密字符串并解析二进制文件中用到的API调用。
字符串是如何加密的?
在这个二进制文件中,我们发现许多地方都引用了0x00401b70处的一个函数调用。实际上,这个调用是用来解密字符串的,因此,不妨将其重命名为decode_strings。要查找对该函数的引用,请右键单击该函数,然后选择References -> Show References to即可。
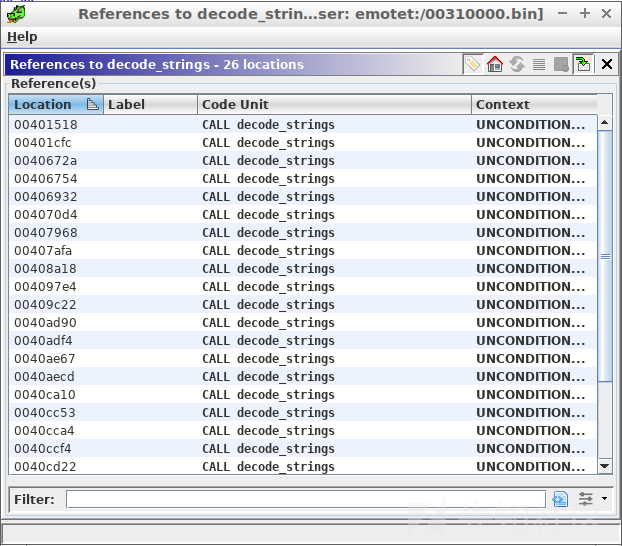
对decode_strings函数的引用

对decode_strings函数的调用
函数decode_strings有两个参数,分别位于ECX和EDX中。其中,ECX中存放的是加密字符串的偏移量,而EDX存放的则是xor密钥。另外,解密后的字符串将存放到在堆中分配的内存中,其地址将存放到EAX中。
(注意:我已将字符串“ecx = offset \n edx = key”添加为该函数的可重复注释(repeatable comment)。具体操作方法为,右键单击地址,然后选择Comments -> Set Repeatable Comment,或键入;即可)
位于该偏移量处的第一个dword与进行异或操作后,就会得到字符串的长度。之后,根据前面得到的字符串长度,对后面相应数量的dword进行异或处理。
现在,我们将为读者介绍最为激动人心的部分——使用Ghidra通过python脚本自动完成上述操作。
使用Python完成自动解密

脚本管理器图标
在Ghidra的顶部的工具栏中,我们可以看到如图所示的图标。点击该图标,就会打开脚本管理器。此外,我们也可以通过Window -> Script Manager来打开它。
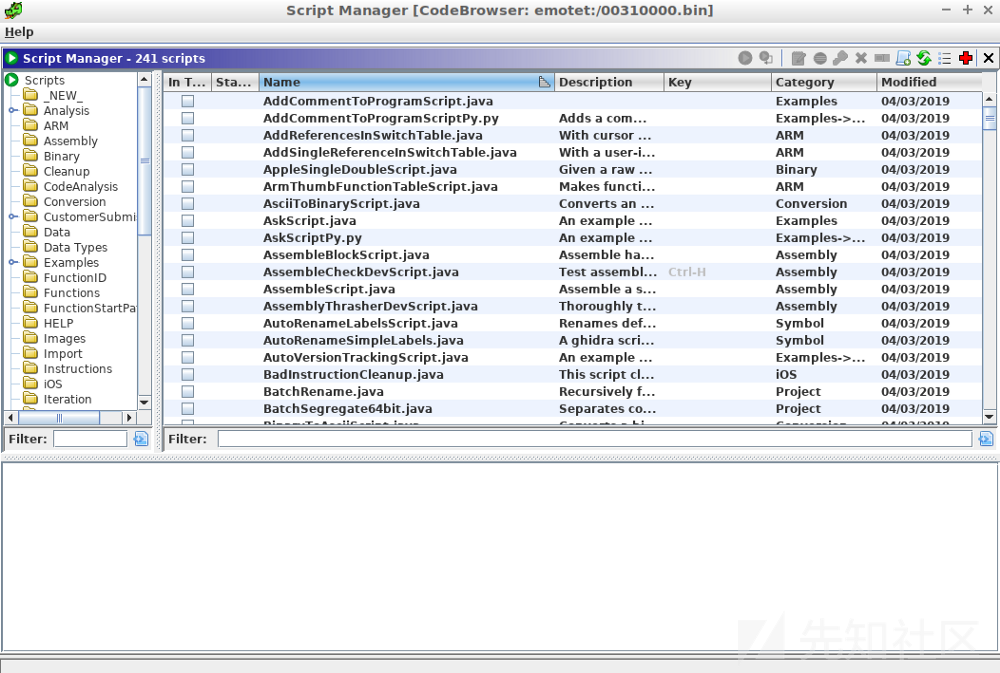
脚本管理器
打开脚本管理器后,我们会看到许多使用Java或Python语言编写的脚本,这些都是软件自带的。此外,脚本管理器还提供了许多python脚本示例。所以,要想学习如何编写python脚本,我们可以通过.py过滤相应的脚本。通过Python Interpreter,我们还可以使用Jython与Ghidra的Java API进行交互。至于Java API的文档,可以在Ghidra安装目录下的docs文件夹中的压缩文件中找到。

新建脚本图标
要新建python脚本,可以点击上图所示的图标;或者,我们也可以选择Python,然后输入为脚本指定的名称即可。
示例脚本test.py
此外,建议大家阅读帮助文档(请访问Help -> Contents)中“Script Development”一节的内容,那里详细介绍了创建新脚本时生成的各种元数据标记。
我已将脚本上传到我的github repo中,访问地址为https://github.com/0xd0cf11e/ghidra/blob/master/ghidra_emotet_decode_strings.py。

解密后的字符串以注释的形式显示
该脚本的思路就是,在将偏移量保存到ECX的指令旁边,以注释的形式显示解密后的字符串。

二进制文件中修补的字节。
然后,修补二进制中的字节。

首先,找出引用decode_strings函数的所有代码。

为此,需要遍历所有引用,并找出操作码指令MOV ECX和MOV EDX。实际上,这些指令并不总是位于函数调用之前。所以,为了查找这些操作码,我最多遍历100条指令。
完成上述操作后,执行xor例程,修补相应的字节,并在相应位置写入注释。
上面,我们介绍了如何使用Ghidra来静态分析恶意软件Emotet。我们知道,Emotet通过简单的xor函数对其字符串进行了加密处理。由于在整个文件中都使用了xor例程,手动解密非常繁琐,所以,我们为大家介绍了如何使用Ghidra的脚本管理器编写python脚本,以自动解码字符串。
接下来,我们将为大家演示如何利用类似的方法,来将Emotet中编码为哈希值解析为API名称。
Emotet是如何解析API地址的?
对于这款恶意软件的二进制文件来说,它并没有对API名称字符串进行加密。相反,它将API名称存储为哈希值,以加大安全人员的分析难度。
这些哈希值数组存储在堆栈中,然后,在函数0x401230中通过指针来引用这些哈希值。所以,我们已将函数0x401230函数标记为decodeAPINames。

保存在堆栈中的哈希值

传递给函数的其他参数
首先,在调用decodeAPINames之前需要获取DLL的句柄。为此,该恶意软件通过PEB枚举来查找kernel32.dll和ntdll.dll的句柄。而其余的DLL,则通过LoadLibraryW(DLL名称由xor例程进行了编码)进行加载。
该函数使用这个句柄来读取DLL的导出地址表。同时,它会计算表中的每个API名称的哈希值,并与压入堆栈的哈希值进行比较。如果匹配,则将相应的API地址将保存为文件内部偏移量。
注意,堆栈中并非所有哈希值都是有用的。相反,许多哈希值都是用来滥竽充数的,所以,乍一看该文件的API地址列表硕大无比,实际上,这只是迷惑安全分析人员的假象。
使用Python将哈希值解析为函数名称
这里有一个通过哈希值解析函数名称的脚本,下载地址为: https://github.com/0xd0cf11e/ghidra/blob/master/ghidra_emotet_decode_hash.py。
当然,还有许多其他方法也可以解决这个问题。这里使用的方法一方面需要用户进行参与,同时,还需要将API名称列表保存到一个文件中。正是因为这个过程有些繁琐,因此,我才编写了一个简单的脚本,让它来替我们完成这些准备工作。

来自Kernel32的部分API名称
首先,我编写了一个脚本,用来将DLL的所有导出函数都保存到一个文件中。
然后,用这个脚本来处理ntdll.dll、kernel32.dll、advapi32.dll、shell32.dll、crypt32.dll、urlmon.dll、userenv.dll、wininet.dll和wtsapi.dll。
接下来是找到所有引用decodeAPINames的偏移量。在这个过程中,我在脚本管理器中无意中发现了Ghidra提供的Java脚本ShowCCallScripts.java。根据该脚本名的提示,我将光标放在decodeAPINames函数中,然后运行了该脚本,结果如下所示:

运行ShowCCallScripts.java后,控制台的输出结果
运行该脚本时,需要注意哪个引用的偏移量处的函数解析哪个DLL的API名称的。
例如,0x4079c0处的函数解析crypt32.dll API名称。为什么这么说呢?因为我发现,当调用decode_strings时,其名称是由0x407afa处的函数进行解析的(详见前文)。然后,会在偏移量0x407b3a处调用decodeAPINames。
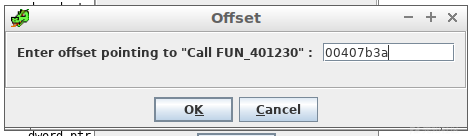
输入引用decodeAPINames的偏移量。
脚本运行时,会要求输入相应的偏移量。例如上图中,我们输入的是407b3a。

crypt32.list文件,其中含有crypt32.dll导出函数名称列表。
接下来,它会提示输入文件名,这里,我们输入的是用来保存crypt32.dll导出函数名称的文件。
在控制台中,我们看到解析了哪些API名称。就crypt32.dll来说,只有一个API名称解析了出来,即CryptDecodeObjectEx,尽管有39个(十六进制为0x27)哈希值被压入堆栈。
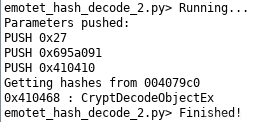
控制台输出结果
之后,该脚本会使用API名称来标记偏移量。

创建CryptDecodeObjectEx标签。
下面是处理kernel32.dll的结果:

kernel32的API名称
希望本文能够对读者有所启发,如果您已经找到了更好的方法来解析哈希值,或发现了与Ghidra有关的有趣的技术,欢迎与我们一起分享。

 发表于 2019-4-28 14:22
发表于 2019-4-28 14:22
 发表于 2019-4-28 16:37
发表于 2019-4-28 16:37







 非常感谢OAO
非常感谢OAO