给你改的能用了,主要原因是,没有携带cookie,并且我发现 cookie会失效,所以你还是要去破解一下cookie生成的JS文件,还有,语法其实也有问题,你自己慢慢看吧
[Python] 纯文本查看 复制代码 from lxml import etree
import requests
import csv
import time
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'cookie': 'cw_tc=7250b31e15626454505637126e49061dae3656054ec8ebad60179b4c90; qchatid=39c4e0a7-00b2-4cd0-bbbf-26d3e6433ebf; language=SIMPLIFIED; JSESSIONID=aaaEzLqo3xaHr9dav7uVw; WINDOW_DEVICE_PIXEL_RATIO=1; _ga=GA1.3.769635160.1562645455; _gid=GA1.3.599078110.1562645455; Hm_lvt_de678bd934b065f76f05705d4e7b662c=1562645455; _jzqa=1.3770715335462188000.1562645515.1562645515.1562645515.1; _jzqc=1; _jzqckmp=1; sid=96f8e12f-0438-4faa-9bba-1163d8024186; SALEROOMREADRECORDCOOKIE=100644811; looks=SALE%2C100644811%2C55538; historyKeywords_SHANGHAI_SALE=%E6%B1%A4%E8%87%A3%E4%B8%80%E5%93%81; historyKeywords_SHANGHAI_NEWHOUSE=%E5%9B%9B%E5%90%88%E9%99%A2|%E6%B1%A4%E8%87%A3%E4%B8%80%E5%93%81; historyKeywords_BEIJING_SALE=%E5%9B%9B%E5%90%88%E9%99%A2; historyKeywords=%E5%B0%96%E6%B2%99%E5%92%80; searchPersonIds=213995097a213772013a2214223a213995003; cookieId=d2b2d395-b904-4817-8825-4a6c737cded5; HOUSE_PRICE_TOKEN=374391848b084135a1e45e27e94d68e8; sec_tc=AQAAALBB3QN54AkAfXkhKGP4oY8lprCj; acw_sc__v2=5d2428f687e081ce36da9330ba33d97f756d7097; CITY_NAME=SHENZHEN; _qzjc=1; _dc_gtm_UA-47416713-1=1; _qzja=1.269318586.1562645515482.1562645515483.1562650874632.1562650874632.1562651053750.0.0.0.11.2; _qzjb=1.1562650874632.2.0.0.0; _qzjto=11.2.0; _jzqb=1.31.10.1562645515.1; Hm_lpvt_de678bd934b065f76f05705d4e7b662c=1562651054',
}
start_url = 'https://shenzhen.qfang.com/sale/f'
def main(writer):
for x in range(1, 5):
url = start_url + str(x)
html = requests.get(url, headers=headers)
time.sleep(1)
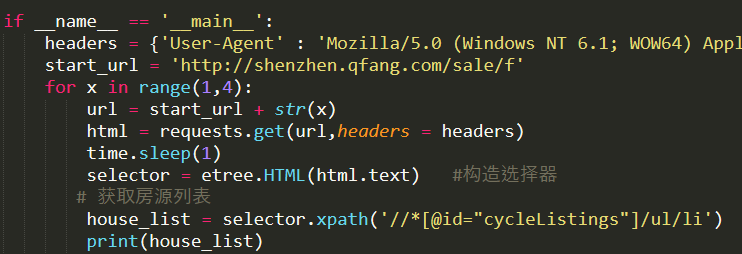
selector = etree.HTML(html.text) # 构造选择器
# 获取房源列表
house_list = selector.xpath('//*[@id="cycleListings"]/ul/li')
for house in house_list:
apartment = house.xpath('./div[1]/p[1]/a/text()')[0].strip() # 房源简介,用text()方法获取文本信息
layout = house.xpath('./div[1]/p[2]/span[2]/text()')[0].strip() # 获取户型
area = house.xpath('./div[1]/p[2]/span[4]/text()')[0].strip() # 面积
floor = house.xpath('./div[1]/p[2]/span[8]/text()')[0].strip() # 楼层
one = house.xpath('./div[1]/p[3]/span[2]/a[1]/text()')[0].strip()
try:
two = house.xpath('./div[1]/p[3]/span[2]/a[2]/text()')[0].strip()
three = house.xpath('./div[1]/p[3]/span[2]/a[3]/text()')[0].strip()
except IndexError:
region = one
else:
region = one+"-"+two+"-"+three
total_price = house.xpath('./div[2]/span[1]/text()')[0].strip() # 总价格
price = house.xpath('./div[2]/p/text()')[0] # 单价
item = (apartment, layout, area, floor, region, total_price+"万", price)
writer.writerow(item)
print('正在抓取', region)
if __name__ == '__main__':
with open('qfang.csv', 'w+', encoding='utf-8-sig', newline='') as csvf:
writer = csv.writer(csvf)
writer.writerow(('房源简介', '房源户型', '房源面积', '房源楼层','房源地址','房源总价'))
main(writer) | 
 发表于 2019-7-9 11:32
发表于 2019-7-9 11:32