本帖最后由 GodStick 于 2019-7-22 19:28 编辑
从这一期就会有很多数学知识了,但是我换了一个图床,不知道会不会显示出来,如果显示不出来我再做替换吧。
例题
为了让大家更加直观的理解这个模型,我们引入一个例题,我们有一组波特兰市的城市住房的价格数据,我们要通过这些数据来找出一个函数,来预测任意面积下的房价,这就是一个简单的线性回归问题。
这里给出的数据是一组房子面积对应的房价
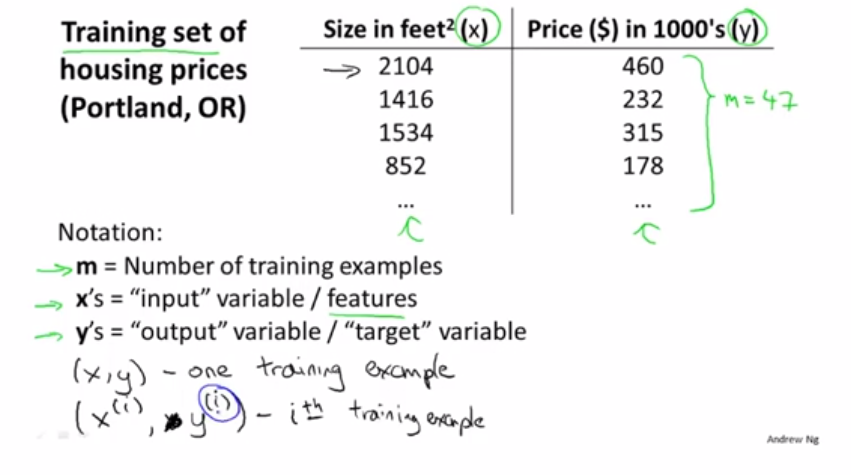
其中m代表训练集,x是输入,y是输出。我们用(x,y)来代表一个训练集,(x^i,y^i)代表第i行训练数据,比如x^2=2104.
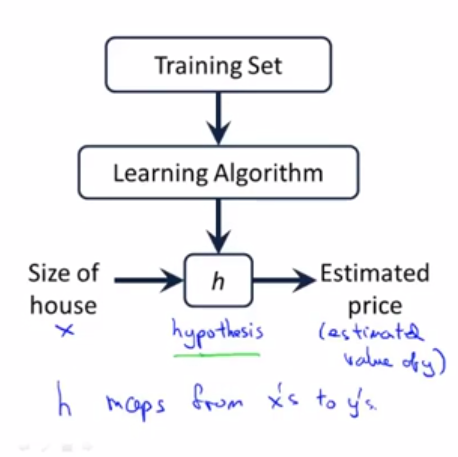
我们训练的目的就是让我们假设一个函数h,使这个函数拟合我们的数据集。
代价函数
我们首先假设函数h(x)= θ0 + θ1x,其中θ0,θ1是这个模型需要变化的参数,我们主要就是训练这两个参数,让函数能达到我们预期的输入输出效果。
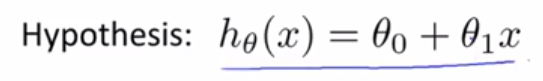
那么如何直观的表现出这个函数的拟合度呢,也就是这个函数的正确度,我们这里就引入了代价函数的概念。
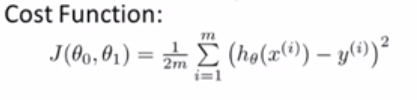
代价函数就是我们函数的输出值和相对应的真实值的方差,我们归回的目的就让方差最小化。
梯度下降
既然我们的目的已经明确了,就是让代价函数最小化,我们怎么才能达到这个目的呢, 我们这里使用梯度下降的方法来达到这个目的,这个方法被广泛应用到机器学习领域之中。梯度下降原理很简单,就是不停的改变θ0,θ1的值,让代价函数得到最小值或者局部最小值。首先我们来看看梯度下降是如何工作的:
这是一个代价函数的图像,首先我们先初始赋值θ0,θ1,在上图的位置标注好了。然后从这个点出发,不断的找到下降的方向,一步一步的下降,直到走到无法继续下降位置。此时的θ0,θ1值就是代价函数的最小值或者是局部最小值。
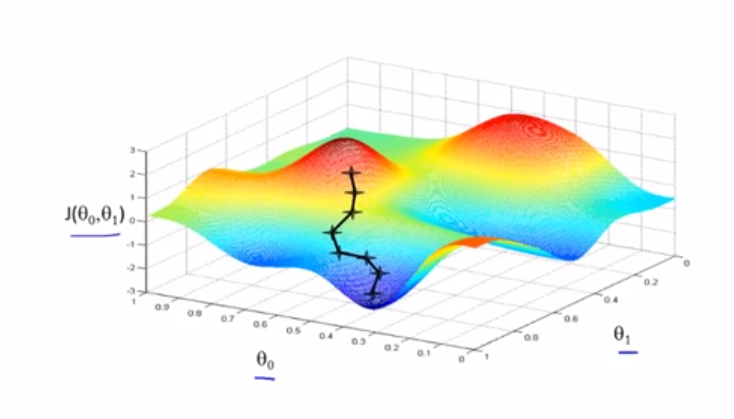
那么怎么用数学公式来表达这个梯度下降的过程呢,其实很简单,只要用这个公式就行了:

这个就是传说中的梯度下降公式,其实原理很简单,就是让参数等于这个参数减去学习率乘于参数的偏导。但要注意的是两个参数的值要同时变化,这个:=号是赋值的意思,不是等于号!!!。如何理解这个公式呢?我们可以选择删去一个参数,只用一个参数来梯度下降,来看一下这个公式的工作原理:
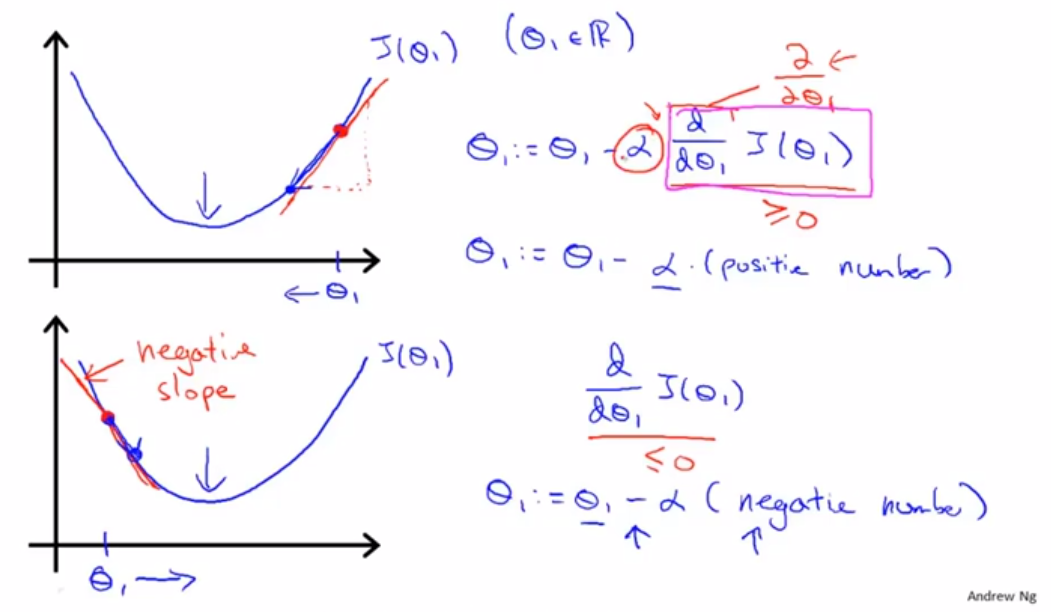
首先假如我们初始赋值在图中位置,我们运用公式。这个偏导数就是这一点在函数中的斜率,我们用斜率来乘于学习率(待会我们再解释这个学习率),再用原θ1的值减去这个乘积,我们可以发现,其实就是向函数下降的方向走了一步,这个学习率就是我们走的一步的长度,学习率大,我们一步下降的就多,斜率大我们下降的也多,但是总的来看下降的步长还是看学习率,应为越是快到最小值,我们的斜率就越小,我们下降的就越慢,当到达最小值的时候,斜率就等于零,参数就停止移动了。我们可以看出图片上面给了当θ1大于或者小于最小值的情况下公式的运算情况,有兴趣的可以自己一步一步的计算试试看。
后记
通过我们得出的公式,你可以用完成一个完整的回归模型。接下来的笔记我会带大家学习,多个x输入情况下的回归建立。 | 
 发表于 2019-7-22 19:19
发表于 2019-7-22 19:19
 |
发表于 2019-7-22 20:08
|
发表于 2019-7-22 20:08




